Connection Lifecycle
Pomerium enables proxying of HTTP and TCP connections, uniformly applying access policies across these connections.
The primary focus of this document is the management of transport layer connections in Pomerium, particularly HTTP requests.
HTTP and TCP connection lifecyle
1. Downstream connection and TLS termination
A client, usually a web browser, initiates a connection to Pomerium.
- This connection can be HTTP/1.1 or HTTP/2.
Pomerium currently does not support QUIC or HTTP/3 transports. Most modern browsers default to HTTP/2 connections for significant performance benefits. In rare circumstances, you may need to force HTTP/1.1 using the codec_type parameter.
- Pomerium presents a server certificate for use based on the provided
certificates. - Optionally, client-side mTLS can be enabled for downstream connections to enforce the use and validation of client certificates.
- Pomerium enforces some minimum TLS requirements for best practice, which are non-configurable.
2. Request initiation
After the transport layer connection is established, the downstream client sends an HTTP request. The proxy parses this request, matches it against the configuration, and determines the upstream service to which the request should be forwarded.
3. Request authorization
The request is authorized according to the policies applied to the Pomerium route before it is forwarded to the upstream service. For more details, see request lifecycle.
4. Upstream connection and request forwarding
- Load Balancing: Pomerium utilizes its load balancing algorithms to select the optimal upstream service instance to process the request. This selection is made from a list of healthy service instances, which is maintained by service discovery and health checking subsystems. The algorithm used for load balancing can be configured and includes options such as Round Robin, Least Request, Random, and more. See Load Balancing Policy options and Load Balancing Policy Config for more information.
- Health Checks: Health checks are key to maintaining the list of viable service instances for load balancing. Pomerium can be set up to routinely check the health of each upstream service instance using methods like HTTP calls, TCP connections, or custom health checks. If an instance fails the health check, it is deemed unhealthy and removed from the list of available instances for load balancing. This ensures that traffic is not directed to instances incapable of handling it.
- Connection & Request Forwarding: Upon selecting a healthy upstream service instance, Pomerium establishes a connection with this instance (if one does not already exist) and forwards the client's request to it. Connection pooling is employed to improve efficiency by reusing existing connections where possible. This behavior can vary depending on whether the connection is HTTP/1.1 (where each connection can be reused but only manages one request at a time) or HTTP/2 (which supports multiple concurrent requests over a single connection).
5. Response forwarding
The upstream service processes the request and sends a response back to Pomerium, which subsequently forwards the response to the client.
6. Connection termination
The connections between the client, Pomerium, and the upstream service are maintained for future requests and are terminated in accordance with the Timeouts.
Request Performance
Web apps, especially modern single-page applications, often handle multiple requests simultaneously. Such apps can benefit significantly from using HTTP/2 transport from the downstream, through Pomerium, and up to the upstream application server.
Typically, HTTP/2 necessitates TLS. Thus, enabling TLS between Pomerium and the upstream applications not only boosts security, but also significantly enhances performance, leading to a smoother and faster user experience.
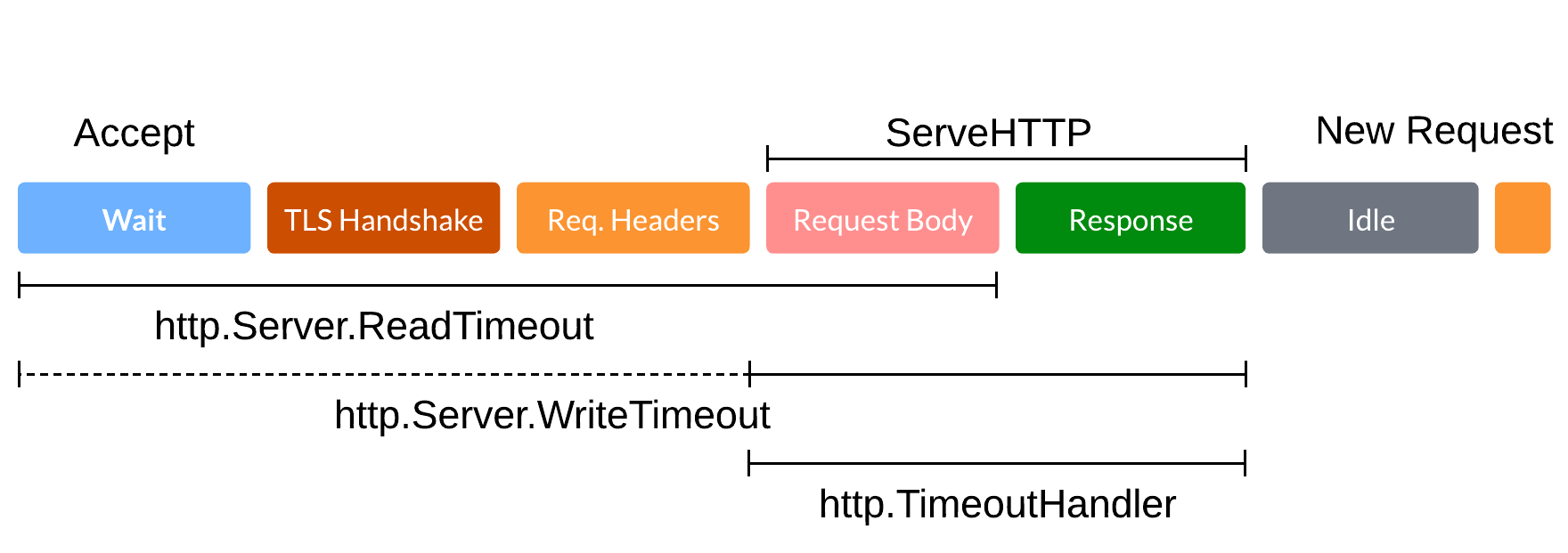
Timeouts
Different timeouts apply at various stages of the connection lifecycle:
-
Upstream Connection timeout: This timeout is applicable when Pomerium is attempting to establish a connection with an upstream service. If the connection cannot be established within the specified timeout, Pomerium will return an error to the client. This timeout, which defaults to 10s and cannot be configured, includes the TLS handshake.
-
Stream idle timeout: This timeout applies to periods of inactivity between the downstream client and Pomerium, or between Pomerium and the upstream service. If no requests are received within the specified timeout, the connection is terminated. This timeout can be configured via the
timeout_idleglobal parameter and can be disabled (but not exceeded) for a specific route using theidle_timeoutvalue. -
Request timeout: This timeout applies to the total time a request can take, which includes connection establishment, request forwarding, processing at the upstream service, and response forwarding. If a complete response is not received within the set timeout, Pomerium will return an error to the client. This timeout can be configured via the
timeout_writeparameter. It may need adjustment, for instance, when handling large uploads. -
Upstream timeout: This timeout applies to the time a request takes to travel from Pomerium to the upstream service and back. It can be configured per-route via the
timeoutparameter and is considered part of the request timeout. By default, it aligns with the globaldefault_upstream_timeoutsetting.
Long-lived connections
Most browser HTTP requests are relatively short-lived. However, certain upstream applications may require long-lived connections that span hours or even days. Examples include Websockets, gRPC streaming, and proxied TCP connections.
From the perspective of HTTP request management, once such a request is initiated, timeouts will apply, potentially terminating the long-lived request. For TCP routes and HTTP routes marked for allow_websockets, timeouts adjust automatically. For connections involving long-lived requests, such as gRPC streaming API or server-sent events, you need to set the route idle_timeout to 0 to disable it.
Draining connections
Most configuration changes (for example, adding or editing a route) are handled seamlessly and do not impact long-lived connections.
However, major changes to global parameters, including TLS certificates, typically require the connection handler to be reconfigured. Internally, this is handled by creating a new handler to accept new requests, while the old handler stops accepting new requests and sends an HTTP/2 GOAWAY or adds Connection: close for HTTP/1 upon request completion, prompting the downstream client to close the current connection.
After a grace period for this transition (~10m), any active connections are terminated.
You may observe the process of connections with envoy_listener_manager_total_filter_chains_draining metric gauge representing many draining processes are there. Normally you should see a value of 1 when there's an active draining process, or 0 if there's no draining currently underway.
If your deployment requires long-lived connections, ensure you use long-lived TLS certificates and avoid other significant global configuration changes.